Что это такое?
Кодировка 1251 — это набор символов, составляющих восьмибитную систему Windows для русифицированных устройств.
Стоит отметить, что он нашел широкое распространение в Европе.
считается одной из самых выгодных кодировок, так как содержит все необходимые символы, используемые в русской типографике. Все символы кириллицы в алфавитном порядке вернуться к содержанию
Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, нужно немного разобраться, что такое кодирование и чем они отличаются. Текстовая информация, как и любая другая, хранится на компьютере в зашифрованном виде. Нам легче думать об этом как о числах. Каждый символ может занимать один или несколько байтов. Windows 1251 — это однобайтовая кодировка, а UTF-8 — восьмибайтовая кодировка. Это означает, что в Windows 1251 можно закодировать только 256 символов.
Поскольку все сводится к двоичной системе вычислений, а байт составляет 8 бит (0 и 1), максимальное количество комбинаций составляет 28 = 256. Юникод позволяет представлять гораздо большее количество символов, а больший размер может назначается для каждого.
Итак, преимущества Unicode следующие:
- В шапке сайта следует указать используемую кодировку. В противном случае вместо символов будет отображаться «кракозяблы». А Unicode является стандартом для всех браузеров — они захватывают его на лету по умолчанию.
- Символы сайта останутся неизменными независимо от страны, в которой загружен ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочей станции заказчика. Житель Португалии, очевидно, использует клавиатуру и все программное обеспечение, включая операционную систему, на своем родном языке. На вашем компьютере, скорее всего, вообще нет Windows 1251. И если да, то даже русские сайты не будут нормально открываться. Юникод, в свою очередь, жестко запрограммирован в любой операционной системе на любом языке.
- UTF-8 позволяет кодировать несколько символов. На данный момент используется 6 байтов из 8, а русские символы кодируются двумя байтами.
Поэтому предпочтительнее использовать универсальное кодирование, чем узкоспециализированное кодирование, которое используется только в славянских странах.
Немного из истории
С началом 90-х, после распада СССР, границы России открылись.
Поэтому техника европейских стран стала постепенно проникать в страну.
Изначально все они были запрограммированы на английском языке.
В то же время Интернет начинает активно распространяться.
В результате возникла необходимость в кратчайшие сроки русифицировать все оборудование и программное обеспечение. В связи с этой необходимостью появилась кодировка 1251. С ее помощью буквы славянского алфавита корректно отображаются на компьютерах.
Это означает, что стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинец
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог» офисы Microsoft начали активно развивать эту кодировку.
За основу были взяты самостоятельно написанные разработки рядовые.
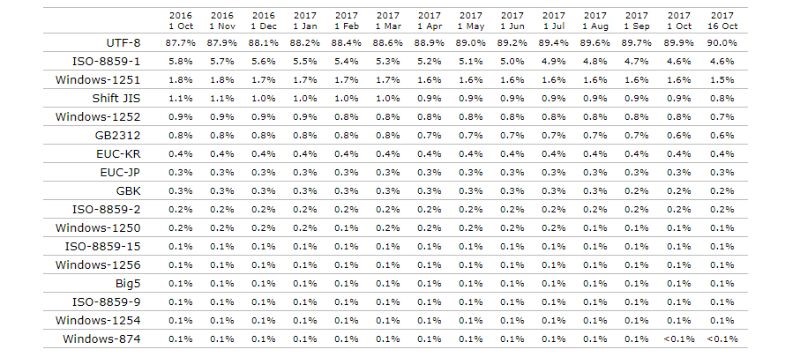
Однако технический прогресс не стоит на месте, поэтому в последнее время Unicode UTF-8 нашел широкое распространение.
Он содержит около 90% веб-ресурсов. Как и в случае с 1251, используется менее 2%.
Читайте также:
Что такое regedit Windows и как им правильно пользоваться
Коды ошибок Windows 10. Как исправить
Как скачать Windows 10 Creators Update: все способы
Влюбленные геймеры: обзор обновления Windows 10 Creators Update
вернуться к содержанию
Описание специальных (управляющих) символов
Первоначально управляющие символы ASCII (диапазон 00–31 плюс 127) были разработаны для управления аппаратными устройствами, такими как телепринтеры, перфоленты и т.д.
Управляющие символы (кроме горизонтальных табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
UTF-8 против 1251
Вся информация, хранящаяся на компьютере, зашифрована.
Можно предположить, что символ имеет вес порядка 1 байта. 1251 — это однобайтовая кодировка, а UTF-8 — восьмибайтовая кодировка.
Таким образом, можно сделать вывод, что первый вариант способен запрограммировать 256 символов.
Что касается второго варианта, то он представляет собой большее число. К тому же для этого отводится большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
- Вверху нужно указать кодировку, необходимую для использования. В противном случае вместо обычных символов появляются неразборчивые иероглифы. Используя UTF-8 (который считается более универсальной кодировкой), все переводы и дешифрование выполняются автоматически
- Независимо от страны, в которой загружена страница, символы останутся неизменными. Важно отметить, что местоположение в данном случае не имеет значения. Главное, на что следует обратить внимание, — это языковые серверы, используемые пользователем. Каждый человек использует программное обеспечение на своем родном языке. Для жителей Европы 1251 будет недоступен из-за использования латинского алфавита. В результате можно сделать вывод, что русскоязычные сайты не будут открываться в правильном формате. Что касается Unicode, он присутствует в любой операционной системе
- Второй тип имеет возможность кодировать несколько символов. Сегодня стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодирования достаточно двух байтов.
В связи с перечисленными выше различиями можно сделать вывод, что универсальная кодировка более актуальна для использования, чем 1251, так как она подходит только для славянской языковой группы.
Для профессиональных программистов и технических специалистов знание кодирования 1251 является необходимым условием для тщательной работы.
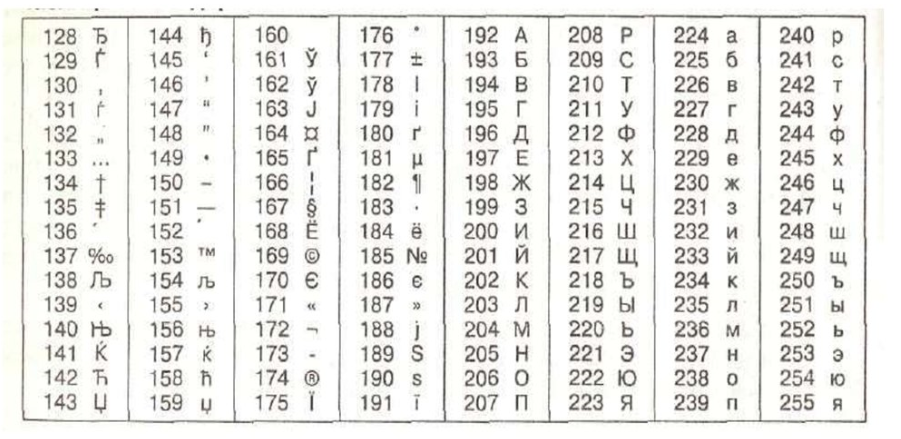
Для быстрого и удобного запоминания символов чаще всего используется следующая таблица:
вернуться к содержанию
Экспресс
—
- Что меня ждет ?
- Анализ отношений с партнером
- Что ты можешь сказать обо мне?
- Нумерологическая карта
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения этой проблемы достаточно использовать текстовый редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей идеально подходит «Блокнот ++» (ссылку для скачивания можно найти в моем Twitter-е).
Скачайте и установите «Блокнот ++» на свой компьютер++».
Запустив «Блокнот ++», напишите те же строки в документе, который мы написали ранее в стандартном блокноте.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого перейдите в меню «Кодировки> Кодировки> Кириллица> OEM-866»
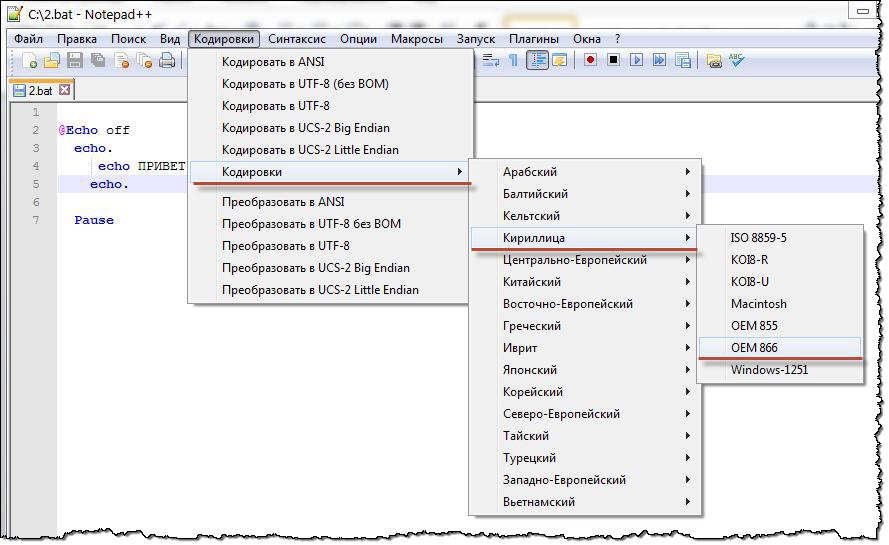
а теперь сохраните файл с именем «2.bat» и запустите его! В стартовом поле появляется лицо.
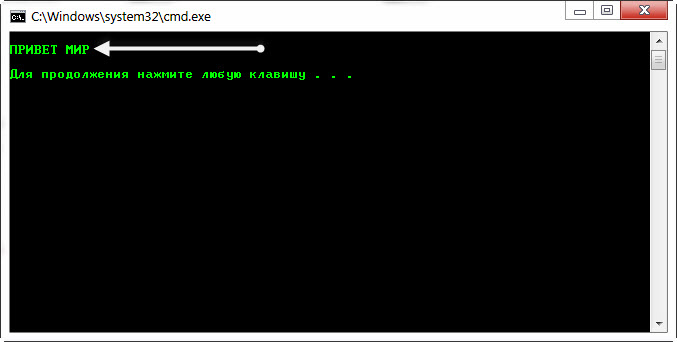
Как видите, русский текст в CMD отображался как положено.
Продукты
—
- Полный нумероскоп
- Персональный гороскоп на 2022 год
- Мастер удачи
- Детектор совместимости
- Печать одиночества
- Календарь Гименея
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке появляются непонятные символы, вопросительные знаки или иероглифы, довольно распространена.
Однако исправить ситуацию можно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что кодировка 1251 упала в Windows 7.
Начиная с восьмой версии активно используется UTF-8.
Чтобы исправить проблему как можно быстрее, вы можете использовать команду CHCP 866, но это только временная мера и не решит проблему полностью.
Обычно для полного устранения проблемы используется реестр:
- Для вызова командной строки нажимаем комбинацию клавиш Win и R. Пишем regedit, открывающий специальный регистр
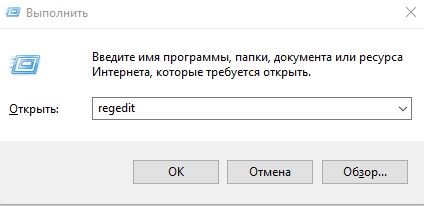
- Как показано на рисунке, мы находим соответствующую папку HKEY_CURRENT_USER и затем выбираем Console. Далее посмотрим, какой код установлен для страниц (Code Page). Если номер не 866, что, скорее всего, будет, проблема определена правильно
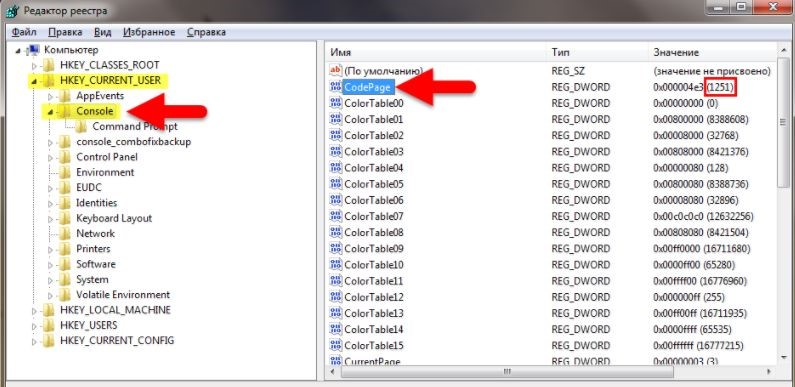
- Исправьте строку с десятичным значением
- Чтобы изменить, произошли ли какие-либо изменения, просто откройте и снова вызовите командную строку.
вернуться к содержанию
Почему до сих пор используется 1251
1251 по-прежнему пользуется большой популярностью у разработчиков интернет-ресурсов по нескольким причинам:
- Многие программисты php используют стандартную кодировку, потому что операционная система Windows поддерживает ее по умолчанию. И хотя в последнее время разработчики начали активно внедрять UTF-8, 1251 до сих пор не сдает своих активных позиций
- Если взять в качестве примера старую версию MySQL до четвертой, то стоит отметить, что при включении тестового режима в UTF-8 возникло много ошибок. Только после версии 4.1 было исправлено множество «глюков». Есть категория программистов, которые остаются верными 1251, а их последователи рьяно следуют их примеру и больше ничем не воспользуются
- Поскольку символ в системе 1251 весит меньше (один байт), вполне логично, что по сравнению с последним вариантом есть некоторая экономия.
По сравнению с этой кодировкой UTF-8 считается лучшим вариантом, поскольку он может распознавать больше символов.
Есть и другие аргументы, которые активно поддерживают использование этой системы:
- вы можете включить любой символ из набора Unicode. Также логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти абсолютно все, от стандартных смайлов до апострофов. Их использование возможно в любом документе. Кроме того, их также можно прочитать в редакторе, что исключает вероятность появления неразборчивых символов
- Раньше считалось, что современный utf занимает больше места. В результате оказалось, что даже символы весят всего один байт. Следовательно, стоит сделать вывод, что увеличения веса страницы не происходит, и его использование столь же просто. Однако если используется только русский алфавит, то в этом случае размер будет увеличен вдвое, так как изначально кириллица в систему не включена
- Система считается одной из самых универсальных, которые уже смогли получить. В этом случае вы можете создавать сайты для любого населения мира. Вам больше не нужно думать о том, какая кодировка используется, поскольку Unicode — универсальная вещь
- UTF — лучший способ работы со страницами php.
Читайте также:
Почему Windows 10 не запускается: эффективные решения
Безопасный режим в Windows 10: как включить, как настроить и что делать, если не работает
Как удалить пароль с компьютера с Windows 10? Три самых простых способа
Как отключить автоматические обновления в Windows 10: руководство
важно отметить, что многие разработчики изначально начали использовать 1251.
И хотя сейчас тенденции изменились, приверженцы именно этой кодировки остались, а значит, она продолжает пользоваться большой популярностью у пользователей. ,
Некоторые думают, что универсальный utf — хорошее решение, которое установлено для современных ресурсов, но 1251 — проверенный алгоритм для стран, использующих кириллицу.
Следует отметить, что в большинстве случаев используется автоматическое переключение. Так, например, если вам нужно прочитать информацию на иностранном или русском языке, вам просто нужно изменить кодировку на текущий формат.
спрос на 1251, вероятно, в будущем станет еще меньше, и на смену ему придут новые проверенные системы. Однако сегодня многие все еще им пользуются.
также важно учитывать, что знание английского языка является обязательным условием для работы с utf.
![]()
Переход к Unicode
Развитие Интернета, увеличение количества компьютеров и бесполезная трата памяти привели к проблемам, вызванным путаницей в кодировании, которая начала перевешивать экономию памяти. Это было особенно заметно в Интернете, когда текст, написанный на одном компьютере, нужно было правильно отображать на многих других устройствах. Это создавало огромные проблемы как для программистов, которым приходилось решать, какую кодировку использовать, так и для конечных пользователей, которые не могли получить доступ к интересующим текстам.
В результате в октябре 1991 года появилась первая версия общей таблицы символов под названием Unicode. На тот момент он состоял из 7161 различных символов из 24 мировых писаний.
В Unicode постепенно добавлялись новые языки и символы. Например, в середине 1992 года в версию 1.0.1 было добавлено более 20 000 китайских, японских и корейских символов. Текущая версия уже содержит более 143 000 символов.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово компьютер можно перевести с английского как калькулятор, а в 20 веке в СССР, до распространения термина компьютер, использовалось сокращение computer — электронный компьютер.
Курс: «Введение в операционные системы». Это бесплатно
Все компьютеры, на которых они работали, были числами. Основным заказчиком и двигателем появления первых моделей были оборонные предприятия. Компьютеры использовались для расчета параметров полета баллистических ракет, самолетов и спутников. В 1950-х годах вычислительные мощности компьютеров начали использоваться для:
- прогноз погоды;
- расчеты экспериментальной и теоретической физики;
- расчет заработной платы сотрудников (например, компьютер LEO использовался для нужд компании, владеющей сетью чайных);
- предсказание результатов президентских выборов в США (1952, компьютер UNIVAC).
Компьютеры и числа
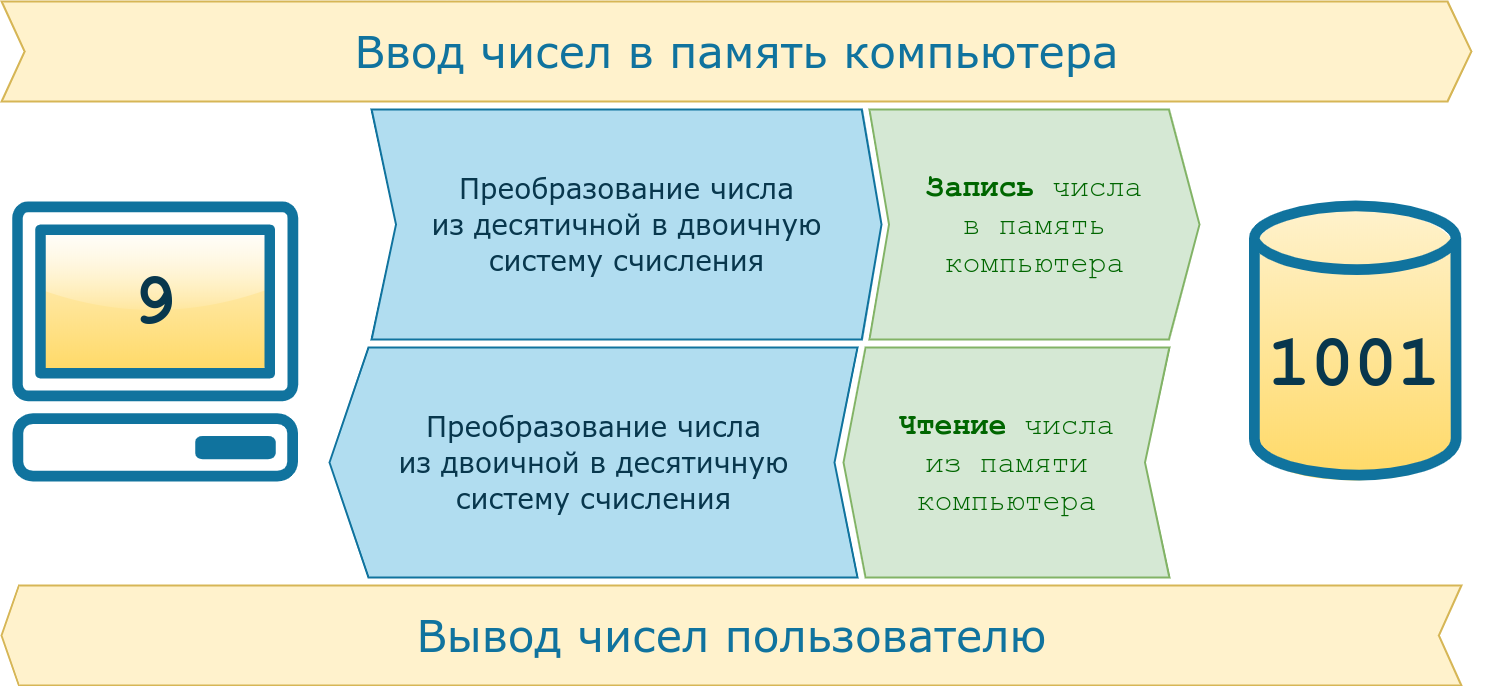
Цели, для которых были разработаны компьютеры, привели к созданию архитектуры, предназначенной для работы с числами. Они хранятся на компьютере следующим образом:
- Число из десятичной системы счисления преобразуется в двоичную, т. Е. Набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать как 11, а 9 — как 1001. Подробнее о системах счисления читайте в соответствующем руководстве.
- Полученный набор нулей и единиц сохраняется в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.
В конце 1950-х годов лампы накаливания были заменены полупроводниковыми элементами (транзисторами и диодами). Внедрение новых технологий позволило уменьшить габариты компьютеров, повысить скорость и надежность расчетов, а также повлияло на конечную стоимость. Если первые компьютеры были дорогими конструкциями, которые могли себе позволить только государства или крупные корпорации, то с использованием полупроводников стали появляться серийные, но не персональные компьютеры.
Компьютеры и символы
Постепенно компьютеры начинают использоваться для решения не только вычислительных или математических задач. Возникает необходимость обрабатывать текстовую информацию, но с буквами и другими символами дело обстоит сложнее, чем с цифрами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя разными символами «а» и «А» в зависимости от регистра.
Также цифра «один» может быть представлена в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы другие.
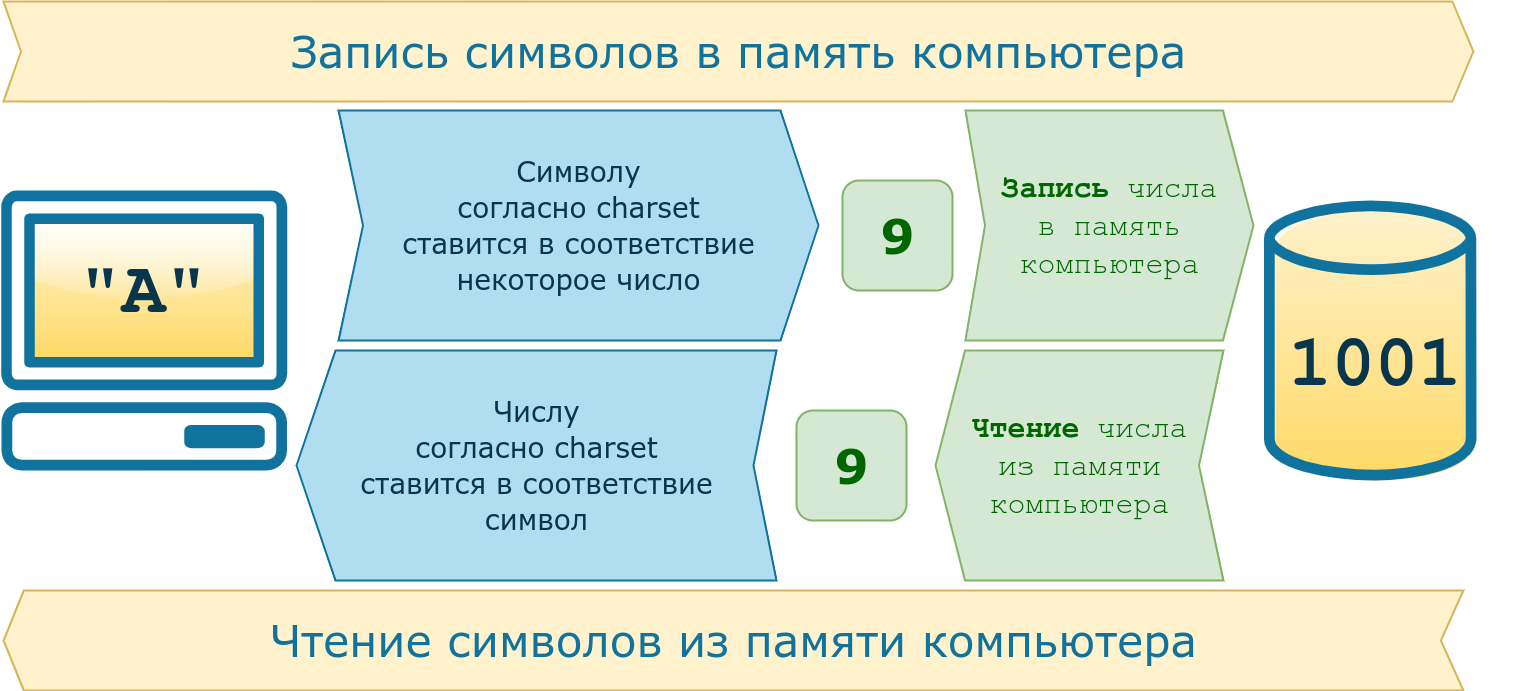
Компьютеры были созданы для работы с числами; они не могут хранить символы. Когда информация вводится в компьютер, символы преобразуются в числа и сохраняются в памяти компьютера как обычные числа, а когда информация выводится, происходит обратное преобразование чисел в символы.
Правила преобразования символов и чисел были сохранены в виде набора символов. В соответствии с этой таблицей каждый компьютер спроектировал свое собственное уникальное устройство ввода / вывода (например, клавиатуру и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной производственной компании. Например, у IBM было около 20 конструкторских бюро, каждое из которых разработало свою модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи сформирована необходимая таблица символов и разработаны устройства ввода / вывода информации.
За это время начинают формироваться сети, объединяющие несколько компьютеров. Так, в 1958 году они создали полуавтоматическую систему наземной среды (SAGE), которая объединила радиолокационные станции США и Канады в первую крупномасштабную компьютерную сеть. В то же время, чтобы результаты вычислений с одних компьютеров можно было использовать на других компьютерах в сети, они должны были иметь одинаковые таблицы символов.
В 1962 году IBM сформулировала два основных принципа развития своей линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, способным решать различные проблемы.
- Компьютеры должны быть совместимы друг с другом, то есть должна иметься возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System / 360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволяло клиентам гибко выбирать компьютер. Модульность систем породила новый сектор: производство модулей обработки, совместимых с System / 360. Компаниям не нужно было производить весь компьютер, они могли выйти на рынок с отдельными совместимыми модулями. Все это привело к еще большему распространению компьютеров.
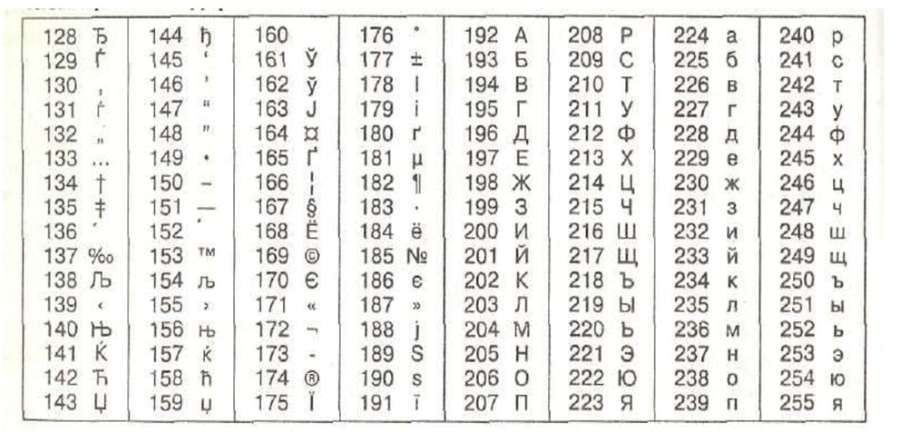
Таблица кодировки Windows 1251
Программистам и разработчикам веб-сайтов иногда необходимо знать номера символов. Для этого используются специальные таблицы кодирования. Ниже представлена таблица для Windows 1251.
Недостатки и достоинства
UTF-8, в отличие от универсальной кодировки Windows-1251, содержит буквы из разных алфавитов. Есть даже UTF-128, где вообще есть все языки: теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 беднее, буквы занимают гораздо меньше места и занимают только один байт памяти, как в 1251. UTP содержит редкие символы из других языков или специальные символы. Они весят 5-6 байт, но редко используются в документе.
Эта кодировка более продумана и поэтому по умолчанию используется большинством приложений. То есть, если вы не укажете программе, какую кодировку вы используете, первое, что она проверит, — это UTF-8 .
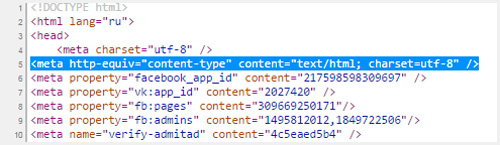
Когда вы создаете html-документ для сайта, вы сообщаете браузерам, на какую таблицу смотреть при расшифровке записей.
Для этого вам нужно поместить следующие данные в тег заголовка. После символов charset = идет UTF или Windows, как в следующем примере.
Если в будущем вы захотите что-то изменить и вставить предложение на албанском по этой таблице транскрипции, то ничего не получится, потому что кодировка не поддерживает этот язык. UTF-8 позволит вам сделать это без проблем.
Если вас интересует правильное создание сайта, то могу порекомендовать курс Михаила Русакова «Создание и продвижение сайта от А до Я».

В нем много: 256 уроков по HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования, вы сможете понять, как монетизировать сайт, т.е получать прибыль быстрее и больше. Один из немногих курсов, который так подробно объяснит все, что вам нужно.
См. Также: Каким должен быть идеальный файл robots.txt для сайта WordPress. И как быстро внести изменения в существующий файл
Сам я уже год учусь в школе блогеров Александра Борисова. Это занимает во много раз больше времени, конца и предела еще не видно, но от этого не менее исчерпывающе и дисциплинированно. Мотивирует продолжать развиваться.
Что ж, если у вас есть какие-либо вопросы, вам не нужно искать в Интернете. Всегда есть грамотный наставник.

Что-то я отклонился от темы. Вернемся к кодировкам.
Что делать, если слетела кодировка командной строки?
Иногда вы можете столкнуться с ситуацией, когда в командной строке отображаются искаженные символы вместо русского языка. Это означает, что существует проблема с кодировкой командной строки Windows 7. Почему 7? Потому что, начиная с восьмой версии используется UTF-8, а в семерке еще и Windows 1251.
В то же время решить проблему может команда chcp 866. Текущая сессия будет работать нормально. Но чтобы кардинально исправить ошибку, нужен лог.
- Нажмите Win + R и введите regedit. Вы попадете в редактор реестра.

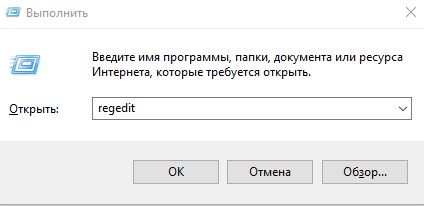
- Перейдите в ветку HKEY_CURRENT_USER Console и посмотрите, какое значение имеет CodePage. Скорее всего, вы увидите что-то другое, кроме 866 (правильно).
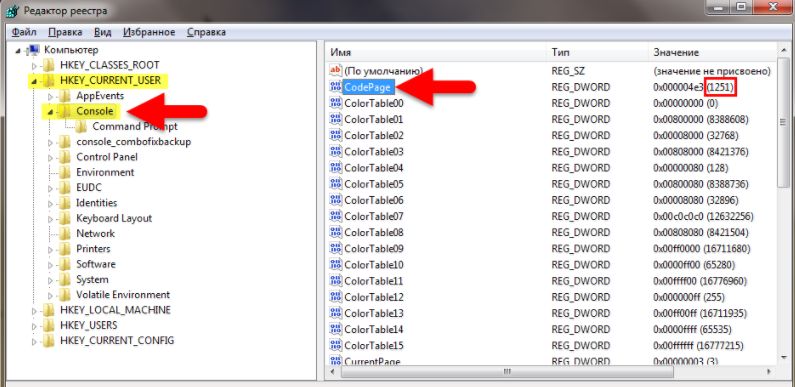
- Исправьте до 866 в десятичном разряде».
- Закройте и снова откройте командную строку. Ситуация должна улучшиться.
Я желаю тебе хорошего дня!
+ 4 — 1 4 1
Износ батареи ноутбука: как определить? Назад Что делать, если файл Excel не открывается? Далее Читайте также. Все по теме 
Формула Excel «Если не пусто, то…»
11.08.2021 Эльвира 
Удалить, нельзя помиловать: обновление Windows тормозит игры
27.04.2021 Эльвира 
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим были разработаны телетайпы. Телетайп — это система для передачи текстовой информации на расстояние. Два принтера и две клавиатуры (фактически электромеханические пишущие машинки) были соединены попарно проводами. Текст, набранный на клавиатуре первым пользователем, распечатывается на принтере вторым пользователем и наоборот. Так, например, до начала 1970-х годов между президентом США и руководством СССР была организована «горячая линия.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по кабелю. При этом не всегда используется двоичный код, например, в азбуке Морзе используются 3 символа: точка, тире и пауза. Для телетайпов нужны таблицы символов, в которых строится соответствие между символами и сигналами в проводах. При этом для каждого тикера (пары связанных тикеров) таблицы символов могут иметь свои, в зависимости от решаемых ими задач. Например, язык может быть другим, а значит, и сам набор символов, который был отправлен с помощью устройства. Чтобы оптимизировать работу телетайпа, наиболее популярные (часто встречающиеся) символы были закодированы с помощью кратчайшего набора сигналов, что означает, что в пределах одного языка набор символов может быть другим.
На базе телетайпов были разработаны терминалы для доступа к компьютерам. Этот телетайп не отправлял сообщения второму пользователю, но информация вводилась на удаленном компьютере, который после обработки указанных команд вернул результат в виде ответного сообщения. Это нововведение позволило использовать тогда еще очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер может быть расположен в отдельном вычислительном центре компании или учреждения, а сотрудники в других филиалах или городах имеют доступ к вычислительной мощности компьютера через свои терминалы.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Этот стандарт был разработан в США в 1963 году. 128-символьная таблица получила название ASCII (американский стандартный код для обмена информацией).
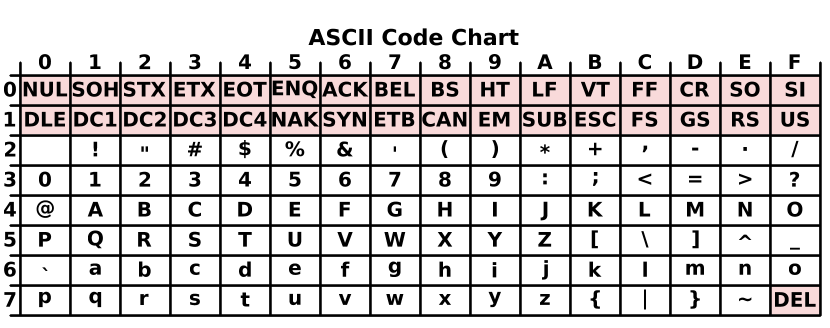
Первые 32 символа в ASCII — это управляющие символы. Они использовались, например, для запуска телетайпа и получения некоторых составных символов. Например:
- символ Ø может быть получен так: мы печатаем O, затем с помощью управляющего кода BS (BackSpace) перемещаем печатающую головку на один символ назад и печатаем символ /,
- символ à получился как BS `
- символ Ç получен как C BS ,
Введение управляющих символов позволило получать новые символы как комбинацию существующих без введения дополнительных таблиц символов.
Однако введение стандарта ASCII решило проблему только в англоязычных странах. В странах с другим шрифтом, например кириллицей в СССР, проблема оставалась.
Кодировки для других языков
Более 20 лет проблема решалась внедрением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные версии кодировок KOI 7 и KOI 8, где 7 и 8 указывают на количество битов, необходимых для кодирования символа, а KOI означает коды обмена информацией.
При дальнейшем развитии систем стали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие 256 символов. Довольно распространенный подход, когда первые 128 символов были взяты из стандарта ASCII, а оставшиеся 128 были объединены с их собственными символами. Это решение, в частности, использовалось в кодировке KOI 8.
Однако эти кодировки не стали единым стандартом. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, поэтому в среде MS Windows использовалась кодировка cp1251. Для греческого языка использовались коды cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, стали нечитаемыми с новыми.
Другие страны с уникальным набором символов также должны иметь свои собственные кодировки. Это привело к путанице и трудностям при обмене информацией. Ниже приведен пример текста, написанного в кодировке KOI8-R и прочитанного в cp851.
| Английский текст. | Английский текст. |
| Это русский текст :-). | — ΦΩΧΧ╦╔╩ Ψ┼╦ΧΨ :-). |
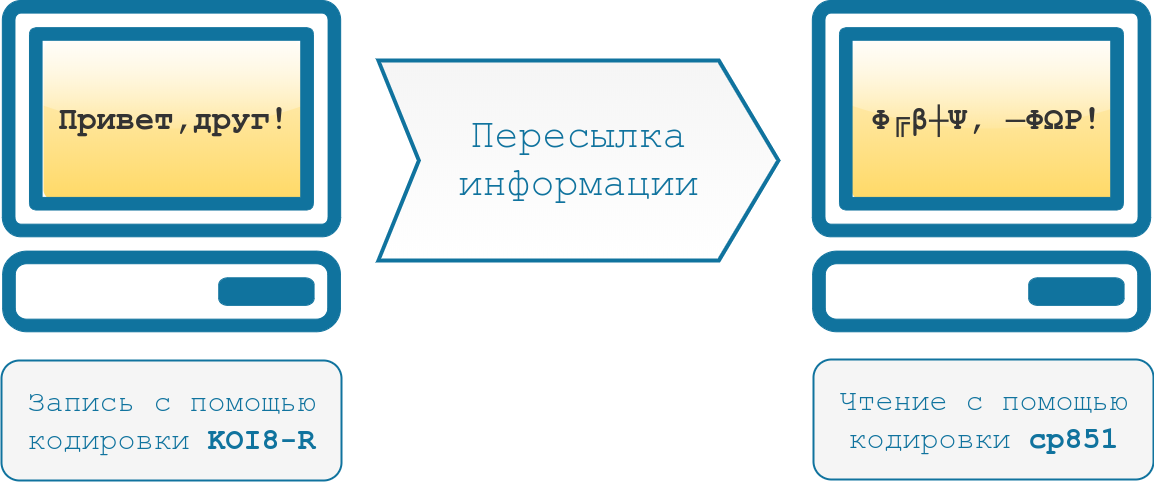
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и английские буквы выглядят одинаково в обеих кодировках. Это делает кириллический текст совершенно неразборчивым.
Однако компьютерная память была дорогой, а связь между компьютерами была медленной. Поэтому было выгоднее использовать кодировки, в которых размер каждого символа в битах был небольшим. Таблица символов состоит из 256 символов. Это означает, что для кодирования одного достаточно 8 бит (2 ^ 8 = 256).
Нумерология
—
- День рождения
- Анализ имени
- Психоматрица
- Квадрат Пифагора
- Будущее на 15 лет
- Чего ожидать в 2022 году ?
- Анализ за неделю и месяц
- Прогнозы на каждый день
- Совместимость
- Профессия
Базы банных
Что касается php, то вообще все страшно. О базах данных я уже говорил, они используются для ускорения работы сайта. Обычно с ними не связываешься, но когда возникает необходимость перенести сайт, становится неудобно.
Трудности случаются с каждым, независимо от стажа работы, стажа и стажа работы. Некоторые страницы базы данных могут содержать все символы, доступные для Windows-1251, другие, например, в шаблонах страниц, в другой кодировке.
Пока не понадобится перенос, все работает и работает, даже если не совсем корректно. Но после переезда начинается беда. В идеале следует использовать только UTP или Windows-1251, но на самом деле все они всегда имеют такие недостатки.
Чтобы дешифрование было согласованным, вам необходимо ввести код mysql_query («SET NAMES cp1251»). В этом случае преобразование будет производиться по другому протоколу — cp1251.
- http://geek-nose.com/windows-1251-kodirovka/
- https://WindowsTips.ru/kodirovka-windows-1251-istoriya-i-primenenie
- https://wm-school.ru/html/html_win-1251.html
- https://numeroscop.ru/znachenie_chisel/chetyrekhznachnye_chisla/chislo_1251.html
- https://window-10.ru/chcp-1251-chto-jeto-znachit-v-batnike/
- https://guides.hexlet.io/encoding/
- [https://start-luck.ru/obsluzhivanie-sayta/kodirovka-windows-1251.html]


